Late last week, I cracked open the Commodore 64 emulator
code once again, in preparation to post it. However, I had to
have a change made to the source control on CodePlex, so I had a
few days to make some changes. So far, it's shaping up quite
nicely:
I went back to the latest version of the Frodo C64
emulator source code and decided to port some of their changes
over to this version. Frodo is written in C and C++, and makes very
heavy use of pointers (and not always safe use of them, as there
was at least one logical overrun). In the previous version, I had
replaced pointers with array manipulation, but I did it in a way
that resulted in an awful lot of array copies floating around. The
arrays were small, so this wasn't a big deal memory-wise, but the
copies all took time in an otherwise time-critical application.
Silverlight doesn't support pointers or unsafe code. Of course,
in elevated trust mode, with a not-really-supported hack, you can
have pointers in Silverlight. However, I wanted to stay away from
that for now as it only works in Silverlight 5, only on Windows,
and won't port to any other sandboxed XAML platforms.
So, I decided to finish what I started and build out some decent
almost-pointerish safe analogs in Silverlight. It was a fairly
large amount of effort, but I thought it might also be interesting
to read about here.
How Pointers Work
If you've never written any C/C++ code, there's a better than
zero chance that you haven't done any explicit pointer manipulation
in your own code. That's not a bad thing, really, as the typical
business application (and many other types) simply doesn't need to
do pointer arithmetic. It's not worth the inherent danger for the
small performance increase. That said, an understanding of
how pointers work is fundamental computer science, and is
important for all developers to know.
It's only when you have to do a lot of memory walking in a
performance-critical application that you run into this.
Programming for microcontrollers like the AVR is a great way to
refresh your memory as to how pointers work and what they bring to
the table.
A pointer is an address in memory and an associated type size.
For example, if we have some fictional 6 byte memory chunk and
declare a pointer to a byte, we end up with something like this
(bonus points if you can figure out the significance of the 5 bytes
starting at 0x01):
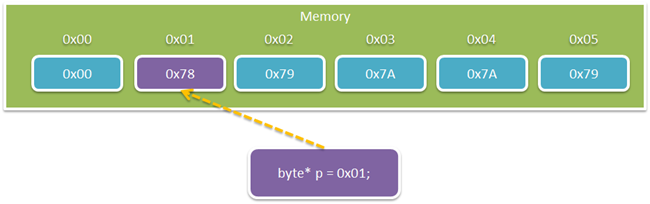
In this case, our byte pointer points to the 8 bits starting at
the address 0x01. You can then manipulate memory using pointer
arithmetic:
byte* p = 0x01; // declare pointer to memory address 0x01
*p = 0x30; // changes value at 0x01 to 0x30 from 0x78
*(p+3) = 0x00; // changes value at 0x04 to 0x00 from 0x7A
while (p < 0x06) // clear rest of memory
*p++ = 0x00;
This is very fast because there really is no indirection. You're
telling the compiler exactly what address to manipulate - it
doesn't have to look anything up.
The size of the pointer variable has to do with the architecture
of the system and its addressing scheme (8 bit, 16 bit, 32 bit, 64
bit), as well as compiler options you select. (In the case of the
Commodore 64, it's all 8 bit.).
You're not limited to the smallest memory unit size, though. If
you wanted to declare a pointer to a 16 bit integer, you'd get this
(assuming "short" is 16 bits on your system):
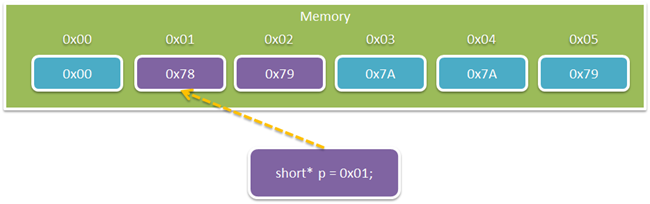
Now, depending on the endian-ness of your
system, the resulting 16 bit number may be 0x7879 (big endian) or
0x7978 (little endian).
It starts to get really powerful when you consider that a
pointer to a structure could also be considered a pointer to a
number of bytes. That allows you to, for example, read a bunch of
bytes from a disk, look at the first couple bytes to figure out
what you have, and then cast the remaining X bytes as the pointer a
directory structure or something. The original C++ C64 emulator
code does a ton of that.
How pointers are used in Frodo
In addition to pointers to structures in byte buffers, frodo
does a lot of string parsing using pointers. In particular, the
1541 drive emulation code uses this for command parsing. In that
code, the first character is often some command identifier, the
next is a delimiter (like a colon) and then some number of
comma-separated values.
In our normal pointer-less code, we'd typically parse the string
and then make copies for each of the individual components. Another
way to deal with it is to simply provide pointers to each of the
sections therefore avoiding making copies of memory. That's
typically how the Frodo code works.
In my first version of the code, I used array indexes to
simulate this. However, that code got incredibly nasty to work
with. I needed another solution.
The Simulated Pointer
You can simulate pointers by simply passing around arrays,
making copies, or even using array indexes. But, as I mentioned,
that code tends to get pretty messy as you have lots of dependent
variables. Instead, I needed a way to encapsulate all of this and
provide pointer-like functionality to handle the majority of the
cases.
- The primary goal of this effort is to make it easy to have code
which is close to 1:1 with its C++ counterparts. For example, if
the C++ code increments a pointer and then assigns a value, I want
to be able to do something similar without having to worry about
which array the pointer points to, or what index value is. The code
won't be 1:1, but I want it as close as possible.
- Another goal of this effort is to minimize the number of times
I copy arrays around. Primarily this is for performance reasons as
the emulator code needs to loop at least one million times a second
(1MHz). Minimizing array copies and object instances helps keep GC
under control as well.
- A non-goal of this effort is efficient use of actual memory. In
fact, my pointer structures use more memory than a pointer just to
simulate a pointer. I'm ok with that.
- Another non-goal is the ability to cast a pointer to a
structure or other complex type. I'd love to do that, but that's
not sandbox-friendly and it's not going to happen that way in this
code.
The C64 code has a number of places where it has memory
allocated in chunks. The most obvious is the main memory of the
system (64K), but there's also 2K in the VIC-1541 drive. Beyond
those, there are several chunks of ROM code which get loaded up and
then mapped into various address locations (cartridges too). In the
emulator code, these are just large arrays of bytes.
If you ever had to simulate an operating system in college,
you've done this before.
Here's an example of two pointers "A" and "B". Pointer A points
to address 0x01 in the memory array. Pointer B points to address
0x05.
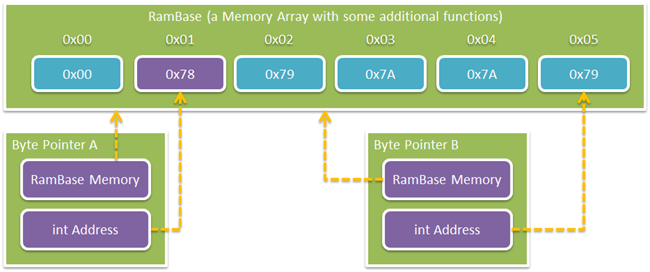
The code to create these looks something like this:
SystemRam ram = new SystemRam();
var a = new RamBytePointer(ram, 0x00);
var b = new RamBytePointer(ram, 0x05);
The RamBytePointer structure represents the pointer. It has a
member Value which can be used to get/set the value at that
position. It also has a number of other helper methods to do things
like copy values from arrays, comparisons with other pointers, etc.
Note that the pointer structure takes a reference to the memory it
is allowed to manipulate. A real pointer has pretty much free run
of memory, so you need to keep the RAM pretty broadly defined if
you need that flexibility.
Here's the current version of the structure. It doesn't do quite
everything I want yet (for example, nothing with comparisons
between pointers, for example), but it does a fair bit.
using System.Diagnostics;
using System.Text;
using System;
namespace PeteBrown.C64.Core.Memory
{
public struct RamBytePointer
{
public RamBytePointer(RamBase memory, int address)
: this(memory)
{
_address = address;
}
public RamBytePointer(RamBase memory)
{
_memory = memory;
_address = 0;
}
private RamBase _memory;
private RamBase Memory
{
[DebuggerStepThrough]
get { return _memory; }
[DebuggerStepThrough]
set { _memory = value; }
}
private int _address;
public int Address
{
[DebuggerStepThrough]
get { return _address; }
[DebuggerStepThrough]
set { _address = value; }
}
public byte this[int offset]
{
[DebuggerStepThrough]
get { return _memory[_address + offset]; }
[DebuggerStepThrough]
set { _memory[_address + offset] = value; }
}
public byte Value
{
[DebuggerStepThrough]
get { return _memory[_address]; }
[DebuggerStepThrough]
set { _memory[_address] = value; }
}
public byte[] GetValues(int length)
{
return _memory.Read(_address, length);
}
public void SetValues(byte[] values)
{
_memory.Write(_address, values);
}
public void CopyFrom(byte[] values, bool incrementPointer)
{
for (int i = 0; i < values.Length; i++)
{
_memory[_address + i] = values[i];
}
if (incrementPointer)
_address += values.Length;
}
public void CopyFrom(char[] characters, bool incrementPointer)
{
for (int i = 0; i < characters.Length; i++)
{
_memory[_address + i] = (byte)characters[i];
}
if (incrementPointer)
_address += characters.Length;
}
public void CopyFrom(string characters, bool incrementPointer)
{
for (int i = 0; i < characters.Length; i++)
{
_memory[_address + i] = (byte)characters[i];
}
if (incrementPointer)
_address += characters.Length;
}
public RamBytePointer NewPointerAtOffset(int offset)
{
return new RamBytePointer(_memory, _address + offset);
}
public static RamBytePointer operator +(RamBytePointer p, int offset)
{
return new RamBytePointer(p.Memory, p.Address + offset);
}
public static RamBytePointer operator -(RamBytePointer p, int offset)
{
return new RamBytePointer(p.Memory, p.Address - offset);
}
public static RamBytePointer operator ++(RamBytePointer p)
{
p.Address += 1;
return p;
}
public static RamBytePointer operator --(RamBytePointer p)
{
p.Address -= 1;
return p;
}
public int IndexOf(byte value, int count)
{
return _memory.IndexOf(value, 0, count);
}
public int IndexOf(char value, int count)
{
return _memory.IndexOf(value, 0, count);
}
public bool Contains(char value, int count)
{
return _memory.Contains(value, 0, count);
}
public bool Contains(byte value, int count)
{
return _memory.Contains(value, 0, count);
}
public string ToString(int startIndex, int length)
{
StringBuilder builder = new StringBuilder();
for (int i = startIndex; i < length; i++)
{
builder.Append((char)_memory[i]);
}
return builder.ToString();
}
}
}
The memory array itself is always created and maintained outside
of this class. It must be valid when the pointer is created.
Operator overloading and Offsets
Of interest is the operator overloading. This allows me to do
things like p++ or p += 1 in order to modify the address that the
pointer is pointing to. That's an important part of keeping the C#
code as similar as possible to the C++ code. However, it doesn't
allow everything the C++ code allows. For example, I can't do the
exact equivalent of this code:
*(p + 5) = 0x05;
*(p - 7) = 0x0A;
If I try to do the equivalent of that, the compiler will barf at
me as it needs an actual LValue on the left side. Instead, code
like that must use something like this:
p[5] = 0x05;
p[-7] = 0x0A;
The code is similar enough that I'm happy with it, although
developers new to the code may raise a few eyebrows at the p[-7]
version.
Converting Strings
Because much of the C++ code treats characters and bytes as
interchangeable (something you can't really do with arrays in C# on
Windows), I also have a few overloads that can take characters or
bytes. This helps clean up the consuming code so it doesn't have so
many casts.
I have helper functions in there to copy from strings. This
helps me easily translate code such as this:
*p++ = 'B';
*p++ = 'L';
*p++ = 'O';
*p++ = 'C';
*p++ = 'K';
*p++ = 'S';
*p++ = ' ';
*p++ = 'F';
*p++ = 'R';
*p++ = 'E';
*p++ = 'E';
*p++ = '.';
Into a nice single-liner like p.CopyFrom("BLOCKS FREE.",
true);
A Structure, not a Class
Note that this is a structure, not a class. Why? Having it as a
structure lets me make copies easily. It's common practice in C/C++
code to have a pointer passed into a function, and then make a copy
of it to increment yourself. For example:
void DoSomething (byte * baseAddress)
{
byte * p = baseAddress;
while (p++ != 0x0A)
...
}
In this example C++ function, p starts off at the same address
as "baseAddress", but then increments it. The value for baseAddress
must be left alone.
Reference types like class in C# are themselves pointers. So,
due to the level of indirection this has, we'd end up modifying the
original value:
class RamBytePointer { ... }
void DoSomething (RamBytePointer baseAddress)
{
RamBytePointer p = baseAddress;
p += 5;
Debug.WriteLine(p.Address);
Debug.WriteLine(baseAddress.Address);
}
// ---------------------------------------
struct RamBytePointer { ... }
void DoSomething (RamBytePointer baseAddress)
{
RamBytePointer p = baseAddress;
p += 5;
Debug.WriteLine(p.Address);
Debug.WriteLine(baseAddress.Address);
}
The first example doesn't work like pointers in C++ at all.
Incrementing p also increments baseAddress. The second example,
however, works as we would expect because p is a copy of
baseAddress, not a reference to it.
The downside of using a struct is there's no inheritance. So, I
instead put a fair bit of the potentially reusable code into the
memory classes instead, and simply call that from the pointer
class.
Summary
Simulating pointers in pointer-free sandboxed platforms is a bit
unorthodox, but can make translating code easier.
This isn't something you're likely to need to do in your own
code, but it an interesting exercise in any case. There's no
downloadable source code yet, as I'm still refining this
implementation. You'll be able to get a version of these classes in
the SilverlightC64
code when I post it in the next week or less. It's taking
longer to swap out all this code than I had intended :)
If you've ever had to do anything like this in your own
code, I'd love to hear about it.